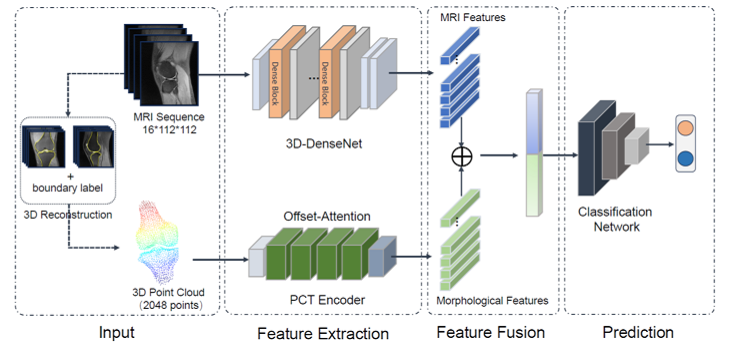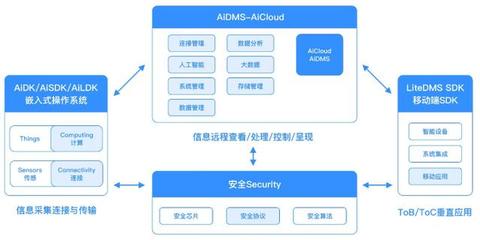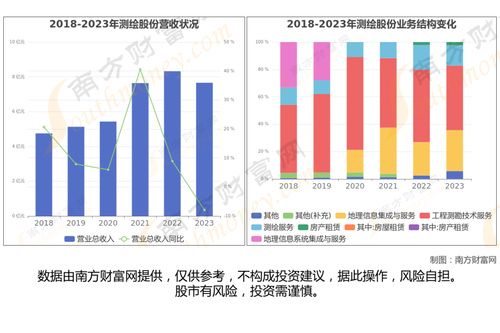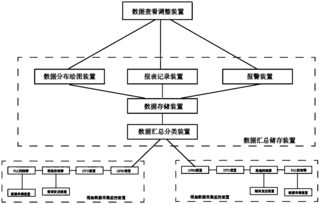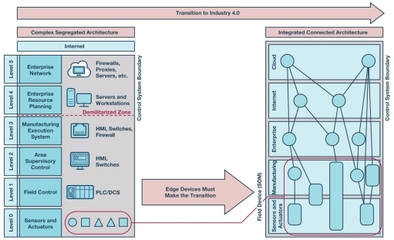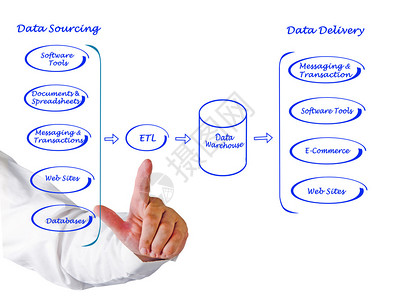
在當今數據驅動的時代,海量信息的涌現對數據處理技術提出了前所未有的挑戰。傳統的批處理模式往往存在延遲高、響應慢的瓶頸,難以滿足業務對實時洞察與敏捷決策的迫切需求。在此背景下,交互式大數據處理與分析技術應運而生,它如同一場靜默的革命,正在重塑我們探索與利用數據的范式。
交互式大數據處理的核心,在于其強調“低延遲”與“高并發”的用戶體驗。它允許分析師、業務人員甚至決策者通過直觀的查詢接口,直接對PB級甚至EB級的數據集發起即時查詢,并在秒級甚至亞秒級內獲得響應。這背后是一系列尖端數據處理技術的融合與創新。
內存計算技術是交互式處理的基石。通過將海量數據加載到分布式集群的高速內存(RAM)中進行分析,而非依賴傳統的磁盤I/O,系統實現了數量級的性能飛躍。以Spark、Flink為代表的現代計算框架,其內存計算引擎能夠將復雜查詢的耗時從小時縮減至分鐘乃至秒級。
預計算與智能索引技術扮演了“加速器”的角色。面對即席查詢(Ad-hoc Query),系統通過列式存儲(如Parquet、ORC)、數據立方體(Cube)或物化視圖等方式,預先對數據進行聚合、排序與索引。當查詢到來時,系統無需掃描全部原始數據,而是快速定位到預計算的結果或相關數據塊,極大提升了查詢效率。例如,Apache Kylin、Druid等OLAP引擎正是這方面的杰出代表。
分布式查詢優化是保證系統高效運轉的大腦。一個交互式查詢可能被分解成數百上千個子任務,在龐大的集群中并行執行。查詢優化器需要智能地制定執行計劃,優化數據Shuffle(混洗)、資源分配與任務調度,以最小化網絡傳輸與計算開銷。向量化執行引擎等技術的引入,進一步壓榨了CPU的處理潛能。
云原生與彈性伸縮架構為交互式處理提供了靈活的土壤。基于Kubernetes的容器化部署,使得計算與存儲資源能夠根據查詢負載動態彈性伸縮。用戶無需為峰值流量過度配置硬件,系統可以自動擴縮容,在保證性能的同時實現成本優化。云服務商提供的Serverless交互式查詢服務(如AWS Athena、Google BigQuery)更是將這一便利性推向了極致。
交互式分析與可視化的緊密結合,構成了技術價值的閉環。強大的數據處理引擎需要與Tableau、Superset、Jupyter Notebook等前端分析工具無縫集成。用戶通過拖拽、點選或自然語言即可發起查詢,結果以豐富的圖表、儀表盤實時呈現,使得數據探索變得直觀而高效,真正實現了從“數據”到“洞見”的平滑過渡。
交互式大數據處理技術正朝著更智能、更融合的方向演進。機器學習與AI的集成,將使系統能夠自動優化查詢、預測熱點數據并進行智能緩存。數據湖倉一體(Lakehouse)架構的興起,則致力于打破事務處理(OLTP)、交互分析(OLAP)與數據科學之間的壁壘,在一個統一的平臺上支持從實時交互到深度學習的全鏈路數據工作負載。
交互式大數據處理與分析技術已不再是錦上添花的工具,而是企業數字化轉型的核心基礎設施。它通過融合內存計算、預計算、分布式優化與云原生等一系列先進的數據處理技術,將數據處理的“速度”與“敏捷性”提升到了新的高度,賦能各行各業在數據的海洋中即時航行,精準捕捉每一朵價值的浪花。