在阿里巴巴的龐大生態系統中,海量數據處理是支撐其業務增長的核心支柱。本文從阿里內部產品案例出發,深入探討海量數據處理系統的架構設計與創新技術,幫助讀者理解其背后的設計思想和實踐經驗。
一、海量數據處理系統的核心架構
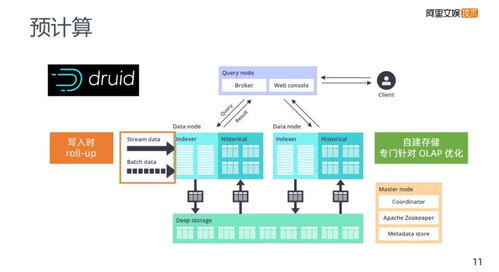
阿里的海量數據處理系統通常采用分層架構,從數據采集、存儲、計算到應用,每層都融入了高度的可擴展性和容錯性。以阿里云MaxCompute(原ODPS)為例,其架構包括:
- 數據接入層:通過DataHub、LogHub等組件,實現多源數據的實時采集與傳輸。
- 存儲層:基于分布式文件系統(如盤古)和對象存儲(如OSS),確保數據的高可靠與低成本存儲。
- 計算層:依托MapReduce、Spark和Flink等引擎,支持批處理與流式計算的統一。
- 調度與資源管理層:采用Fuxi調度系統,實現任務的智能分配和資源隔離。
- 應用層:通過DataWorks等工具,為業務方提供數據開發、治理和可視化服務。
這種分層設計不僅提升了系統的模塊化程度,還使得各層可以根據業務需求獨立擴展,有效應對數據量從TB到EB級的增長。
二、創新數據處理技術的應用
在技術層面,阿里引入了多項創新,以優化性能、降低成本并提高數據處理的智能化水平。
1. 實時與離線一體化計算:
阿里通過Blink(基于Flink的流計算引擎)和MaxCompute的融合,實現了流批一體的數據處理模式。例如,在雙11大促中,系統能夠同時處理實時交易數據和離線分析任務,確保業務決策的及時性與準確性。
2. 智能數據壓縮與存儲優化:
針對海量數據存儲成本高的問題,阿里研發了自適應壓縮算法,根據數據特征動態選擇壓縮策略,平均降低存儲空間30%以上。利用分層存儲技術,將冷熱數據分別存儲于高性能和低成本介質中。
3. 數據湖與數據倉庫的融合:
阿里內部產品如Data Lake Formation和AnalyticDB,實現了數據湖與數據倉庫的無縫集成。用戶可以在數據湖中自由探索原始數據,并通過數據倉庫進行高效分析,兼顧靈活性與性能。
4. AI驅動的數據治理:
借助機器學習技術,阿里構建了智能數據血緣和質量監控系統。例如,DataWorks內置的AI助手可以自動識別數據異常、推薦優化策略,減少人工干預,提升數據可靠性。
5. 邊緣計算與云邊協同:
在物聯網場景下,阿里將數據處理能力下沉至邊緣節點,通過Link IoT Edge等產品實現本地實時處理,并結合云端進行深度分析,降低了網絡延遲與帶寬消耗。
三、實踐經驗與挑戰
盡管阿里的海量數據處理系統在架構和技術上表現卓越,但在實踐中仍面臨諸多挑戰:
- 數據安全與合規:隨著數據量的激增,如何確保數據隱私和滿足全球法規(如GDPR)成為關鍵問題。阿里通過加密、脫敏和權限管控等多層防護機制應對。
- 系統復雜度管理:分布式系統的運維難度高,阿里通過自動化運維平臺和AIOps技術,實現了故障預測與自愈。
- 成本控制:通過資源彈性伸縮和算法優化,阿里在保證性能的將數據處理成本控制在合理范圍內。
四、結語
從阿里內部產品可以看出,海量數據處理系統的成功離不開靈活的架構設計和持續的技術創新。隨著5G、AI和量子計算的發展,數據處理系統將更加智能、高效和普惠。借鑒阿里的經驗,企業和開發者可以構建更適合自身業務的數據處理平臺,助力數字化轉型。
通過本文的分析,希望讀者能深入理解海量數據處理系統的核心要素,并在實際項目中應用這些架構與技術創新。