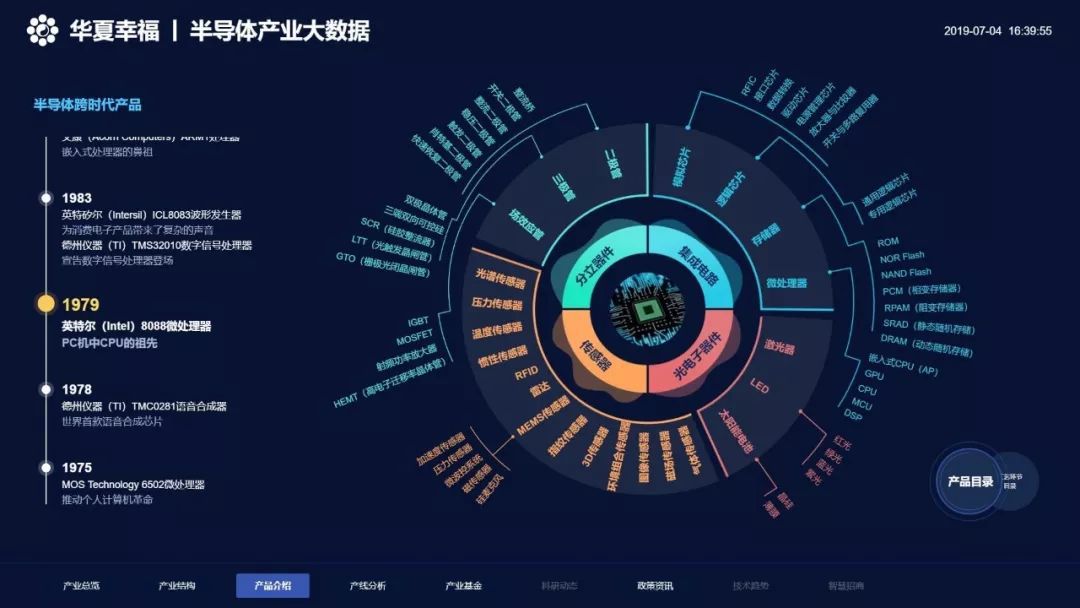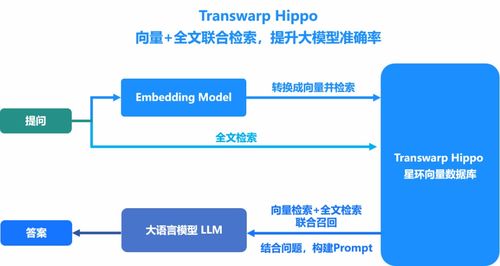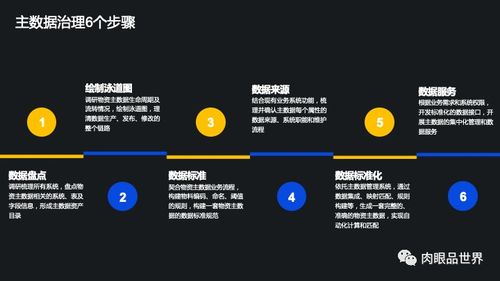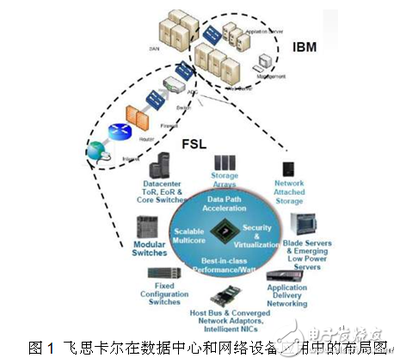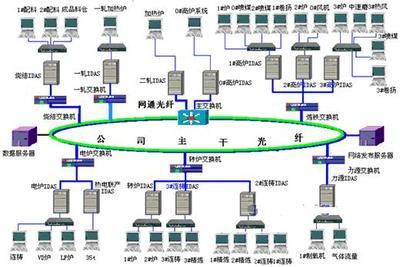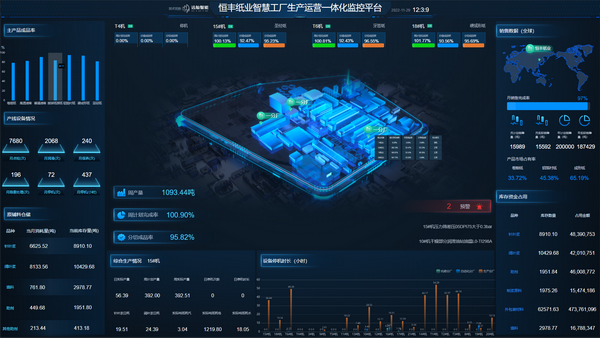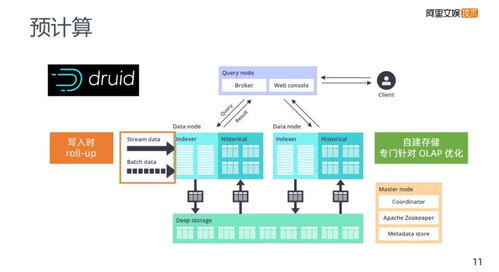
隨著數(shù)字經(jīng)濟(jì)的快速發(fā)展,數(shù)據(jù)處理技術(shù)經(jīng)歷了從傳統(tǒng)數(shù)據(jù)倉庫到現(xiàn)代化數(shù)據(jù)中臺的深刻變革。這一演進(jìn)不僅反映了技術(shù)架構(gòu)的升級,更體現(xiàn)了企業(yè)對數(shù)據(jù)價值挖掘需求的不斷提升。本文將從大數(shù)據(jù)演進(jìn)歷程出發(fā),探討技術(shù)選型的最優(yōu)解。
一、數(shù)據(jù)倉庫時代:結(jié)構(gòu)化數(shù)據(jù)的集中管理
在早期大數(shù)據(jù)處理階段,企業(yè)主要采用數(shù)據(jù)倉庫(Data Warehouse)技術(shù)。這類系統(tǒng)以ETL(抽取、轉(zhuǎn)換、加載)為核心,通過對結(jié)構(gòu)化數(shù)據(jù)的集中存儲和管理,支持商業(yè)智能(BI)和報表分析。典型代表如Teradata、Oracle等傳統(tǒng)數(shù)據(jù)庫,其優(yōu)勢在于數(shù)據(jù)一致性和事務(wù)處理能力,但面對海量非結(jié)構(gòu)化數(shù)據(jù)時顯得力不從心。
二、大數(shù)據(jù)平臺興起:分布式計算的突破
Hadoop生態(tài)系統(tǒng)的出現(xiàn)標(biāo)志著大數(shù)據(jù)處理進(jìn)入新階段。通過HDFS分布式存儲和MapReduce計算框架,企業(yè)能夠以較低成本處理PB級數(shù)據(jù)。隨后,Spark憑借內(nèi)存計算優(yōu)勢進(jìn)一步提升了處理效率。這一階段的技術(shù)選型重點(diǎn)轉(zhuǎn)向可擴(kuò)展性和成本控制,但數(shù)據(jù)孤島和治理難題逐漸顯現(xiàn)。
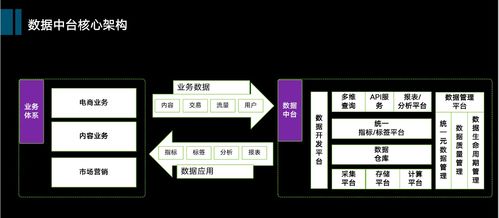
三、數(shù)據(jù)中臺架構(gòu):業(yè)務(wù)價值導(dǎo)向的數(shù)據(jù)服務(wù)
當(dāng)前,數(shù)據(jù)中臺理念正在重塑企業(yè)數(shù)據(jù)架構(gòu)。其核心是通過統(tǒng)一的數(shù)據(jù)資產(chǎn)層,將數(shù)據(jù)能力封裝為可復(fù)用的服務(wù)。在技術(shù)選型上,企業(yè)需要平衡實時處理與批處理、數(shù)據(jù)開發(fā)與數(shù)據(jù)治理等多重需求:
- 實時計算層面,F(xiàn)link因其低延遲和高吞吐成為流處理首選
- 數(shù)據(jù)湖技術(shù)(如Delta Lake、Iceberg)解決了數(shù)據(jù)一致性難題
- 數(shù)據(jù)目錄和血緣分析工具助力數(shù)據(jù)治理
- 云原生架構(gòu)提供了彈性伸縮的基礎(chǔ)設(shè)施
四、技術(shù)選型最優(yōu)解:業(yè)務(wù)場景驅(qū)動的架構(gòu)設(shè)計
最優(yōu)技術(shù)選型應(yīng)遵循以下原則:
- 場景適配性:批流一體架構(gòu)滿足多樣化分析需求
- 成本效益:云原生方案降低運(yùn)維復(fù)雜度
- 演進(jìn)能力:模塊化設(shè)計支持技術(shù)棧平滑升級
- 數(shù)據(jù)安全:貫穿全鏈路的數(shù)據(jù)保護(hù)機(jī)制
從數(shù)據(jù)倉庫到數(shù)據(jù)中臺的演進(jìn)啟示我們,技術(shù)選型沒有絕對標(biāo)準(zhǔn)答案,關(guān)鍵在于構(gòu)建與業(yè)務(wù)發(fā)展同步的數(shù)據(jù)能力體系。未來,隨著AI與數(shù)據(jù)技術(shù)的深度融合,智能數(shù)據(jù)平臺將成為新的演進(jìn)方向。企業(yè)在技術(shù)選型時,既要關(guān)注技術(shù)前沿,更要重視數(shù)據(jù)文化的建設(shè),才能真正釋放數(shù)據(jù)價值。